Gluster學習筆記
MIS最怕碰到的就是硬碟掛點,每次掛點都是一個痛苦的回憶,總是不想碰到下一次,無非最想要的就是Raid,但是好用的Raid都很貴,而Gluster就不失為一個省錢的方案。
安裝
Server端採CentOS7,並以下列指令找新最新版gluster
#yum search centos-release-gluster
…
centos-release-gluster41.x86_64 : Gluster 4.1 (Long Term Stable) packages …
|
以本例來說,Server端所需套件為,
#yum -y install centos-release-gluster41
#yum -y install glusterfs gluster-cli glusterfs-libs glusterfs-server
|
防火牆設定(以下預設會開啟NFS)
#firewall-cmd --zone=public --add-service=glusterfs --permanent
#service firewalld reload
|
在官方的說明文件中有提到
Ensure that TCP and UDP ports 24007 and 24008 are open on all Gluster servers.
Apart from these ports, you need to open one port for each brick starting from port 49152 (instead of 24009 onwards as with previous releases). The brick ports assignment scheme is now compliant with IANA guidelines. For example: if you have five bricks, you need to have ports 49152 to 49156 open.
Apart from these ports, you need to open one port for each brick starting from port 49152 (instead of 24009 onwards as with previous releases). The brick ports assignment scheme is now compliant with IANA guidelines. For example: if you have five bricks, you need to have ports 49152 to 49156 open.
24007與24008是Server端一定要開的Port,然後從49152(若是 3.4版之前,則是從24009)開始(NFS的Port則是從38465 to 38467),共用一個Brick就必須用到1個Port,假設我們要開放2個Brick,則可設定如下:
#firewall-cmd --zone=public --add-port=24007-24008/tcp --add-port=49152-49153/tcp --permanent
#service firewalld reload
|
Client端所需套件為
#yum install -y glusterfs glusterfs-fuse attr
|
Client端的防火牆設定(相對應連線多少Brick,就開多少Port,基本上我是不用NFS與Samba,相關Port參考這裡),這裡要特別說明的是,在volume info可以看到裡面有一個屬性nfs.disable預設是on(此文章後段找一下就有看到),如果想關閉這個設定,會出現一行警告:"Gluster NFS is being deprecated in favor of NFS-Ganesha",所以若想要以NFS開放Gluster的Volume,應該安裝nfs-ganesha-gluster與nfs-ganesha這兩個套件。
#firewall-cmd --zone=public --add-port=111/tcp --add-port=111/udp --add-port=49152-49153/tcp --add-port=38465-38469/tcp --permanent
#service firewalld reload
|
Volume模式
這邊有中文的說明,官方的說明則在此。中文資料 稍舊,英文推介只剩5種推薦模式:Distributed、Replicated、Distributed Replicated、Dispersed與Distributed Dispersed。
選擇那種Volume Type,取決於想要達成的目的。
首先,為什麼要把檔案放在Cluster?不就是怕硬碟掛點丟失資料嗎,如果有錢選擇Raid就好了,沒錢才會用這種方式,所以首先Distributed 模式就被排除了,因為任何一個節點掛掉,資料就救不回來了,所以無法Replicate的是不加以考慮的;Dispersed用網路方式實現Raid,說實在的用這種方式,好處除了可以異地備援外(頻寬要夠快),還不如用Soft Raid來的快。所以只剩 Replicated 一種是比較有價值的。
一顆硬碟可以使用多久?Backblaze的2萬5千顆的分析圖告訴我們一年半內的年故障率是 5.1%,一年半到三年之間故障率降為 1.4%,三年之後又提升至 11.8%,也就是說,大約有 92% 的硬碟可以撐過 18 個月,而有 90% 左右的硬碟可以使用到三年。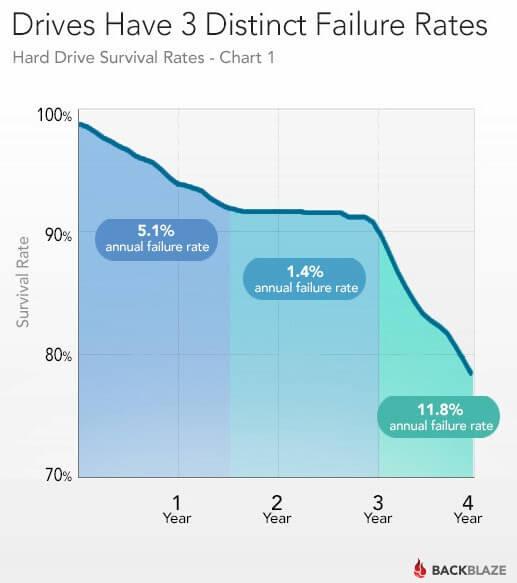
所以我的省錢方案是,先用一台作Gluster,兩年後再加入另外一台節點。
Lab實做
作為測試,我們先準備一台Server與一台Client,稍後再加入另外一台Server。
測試都是以虛擬機方式進行,Server一律加掛一個2G的vdb硬碟。
首先要說明的是,Gluster分享的方式是採目錄分享而不是Mount Point(如硬碟掛載在/mnt,/mnt就是一個Mount Point),我要做的範例是郵件伺服器,因為Postfix本身沒有Native HA,所以我打算Gluster 2個目錄,一個是郵箱 /var/spool/mail 另外一個是家目錄 /home。
首先先設定第一台Server(Domain name 是 gluesterS1)
S1#yum -y install centos-release-gluster41
S1#yum -y install glusterfs gluster-cli glusterfs-libs glusterfs-server
S1##先把/dev/vdb 切出 /dev/vdb1
S1#lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vdb 252:16 0 2G 0 disk
└─vdb1 252:17 0 2G 0 part
S1##格式化 /dev/vdb1硬碟並掛載到 /brick
S1#mkfs.xfs -i size=512 /dev/vdb1 && mkdir /brick && echo '/dev/vdb1 /brick xfs defaults 0 0'>>/etc/fstab && mount -a
S1#lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vdb 252:16 0 2G 0 disk
└─vdb1 252:17 0 2G 0 part /brick
S1##啟動Gluster 服務
S1#systemctl enable glusterd.service && systemctl start glusterd.service
S1##開兩個分享目錄
S1#mkdir /brick/{mailhome,mailspool}
S1##分享Gluster 服務,[force]參數是再次重建時遇錯誤時用強迫建立的方式
S1#gluster volume create mailhome glusterS1:/brick/mailhome [force]
S1#gluster volume create mailspool glusterS1:/brick/mailspool
S1#gluster volume start mailhome && gluster volume start mailspool
S1#gluster volume bitrot mailhome enable
S1#gluster volume bitrot mailspool enable
S1##設定防火牆
S1#firewall-cmd --zone=public --add-port=24007-24008/tcp --add-port=49152-49153/tcp --permanent && service firewalld reload
S1##檢查空間資訊
S1#gluster volume info
Volume Name: mailhome
Type: Distribute
Volume ID: 6724862a-5ff9-4bd5-8d7a-590e87e14ee9
Status: Started
Snapshot Count: 0
Number of Bricks: 1
Transport-type: tcp
Bricks:
Brick1: glusterS1:/brick/mailhome
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
Volume Name: mailspool
Type: Distribute
Volume ID: f17583bc-aa76-4b6a-b309-9ef430d6f223
Status: Started
Snapshot Count: 0
Number of Bricks: 1
Transport-type: tcp
Bricks:
Brick1: glusterS1:/brick/mailspool
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
|
然後安裝Client端
SC#yum -y install centos-release-gluster41
SC#yum -y install deltarpm epel-release glusterfs glusterfs-fuse attr
SC##設定防火牆
SC#firewall-cmd --zone=public --add-port=111/tcp --add-port=111/udp --add-port=49152-49153/tcp --permanent && service firewalld reload
SC##設定郵件掛載目錄
SC#echo "glusterS1:/mailhome /home glusterfs defaults,_netdev 0 0" >> /etc/fstab
SC#echo "glusterS1:/mailspool /var/spool/mail glusterfs defaults,_netdev 0 0" >> /etc/fstab
SC#mount -a && chown :mail /var/spool/mail/
SC##安裝postfix
SC#yum -y install postfix opendkim mailx rsyslog bind-utils
SC##新增用戶
SC#add user kent
SC#add user sylvia
|
若是不想裝一台Client機而只是想測試,其實可以暫時開放防火牆外,加裝 autofs 服務,並設定如下
SC#yum -y install autofs
SC##/etc/auto.misc加二行設定,注意,不可少acl選項
SC#grep glusterfs /etc/auto.misc
gluster -fstype=glusterfs,rw,acl,_netdev :glusterS1:/mailhome
gluster -fstype=glusterfs,rw,acl,_netdev :glusterS1:/mailspool
SC##暫時開防火牆
SC#firewall-cmd --zone=public --add-port=111/tcp --add-port=111/udp --add-port=49152-49153/tcp
SC##重啟自動掛載
SC#systemctl restart autofs.service
SC##查看目錄
SC#ls -l /misc/mailhome /misc/mailspool
|
註:autofs自我mount 可以設定如 mailhome -fstype=glusterfs,rw,acl :localhost:/mailhome
加掛備機
假設兩年後,S1的硬碟使用超過17.5k Hour,我們決定再加一台Gluster Server (Domain Name 是 glusterS2),安裝過程跟 S1一樣(別忘了也要加掛同要的分割空間)。因為本測試的S2是Clone過來的,所以要先重設一些資料
S2#gluster system uuid reset
S2#lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vdb 252:16 0 2G 0 disk
└─vdb1 252:17 0 2G 0
總計 0
|
或者安裝一台新的glusterS2(一樣要加裝一個2G的vdb)
S2#yum -y install centos-release-gluster41
S2#yum -y install glusterfs gluster-cli glusterfs-libs glusterfs-server
S2##先把/dev/vdb 切出 /dev/vdb1
S2#lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vdb 252:16 0 2G 0 disk
└─vdb1 252:17 0 2G 0 part
S2##格式化 /dev/vdb1硬碟並掛載到 /brick
S2#mkfs.xfs -i size=512 /dev/vdb1 && mkdir /brick && echo "/dev/vdb1 /brick xfs defaults 0 0">>/etc/fstab && mount -a
S2#lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vdb 252:16 0 2G 0 disk
└─vdb1 252:17 0 2G 0 part /brick
S2#systemctl enable glusterd.service && systemctl start glusterd.service
S2#firewall-cmd --zone=public --add-port=24007-24008/tcp --add-port=49152-49153/tcp --permanent && service firewalld reload
|
然後到S1進行設定
S1##新增節點
S1#gluster peer probe glusterS2
S1##檢查節點是否加入
S1#gluster peer status
Number of Peers: 1
Hostname: glusterS2
Uuid: 056034ab-8ff1-4ce5-897d-152b4e85ba54
State: Peer in Cluster (Connected)
S1##顯示儲存池中的節點
S1#gluster pool list
| |||||||||
S1##分享目錄加入新區塊,replica 2表示一個檔案至少要儲存兩份在Pool裡(我們也只有2台機器)
S1#gluster volume add-brick mailhome replica 2 glusterS2:/brick/mailhome
S1#gluster volume add-brick mailspool replica 2 glusterS2:/brick/mailspool
S1#gluster volume info
Volume Name: mailhome
Type: Replicate
Volume ID: 6724862a-5ff9-4bd5-8d7a-590e87e14ee9
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: glusterS1:/brick/mailhome
Brick2: glusterS2:/brick/mailhome
Options Reconfigured:
performance.client-io-threads: off
transport.address-family: inet
nfs.disable: on
Volume Name: mailspool
Type: Replicate
Volume ID: f17583bc-aa76-4b6a-b309-9ef430d6f223
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: glusterS1:/brick/mailspool
Brick2: glusterS2:/brick/mailspool
Options Reconfigured:
performance.client-io-threads: off
transport.address-family: inet
nfs.disable: on
|
到S2確認檔是否已複製,結果是我們的郵件伺服器的資料完整總算是有了保障
S2#tree /brick
/brick
├── mailhome
│ ├── kent
│ └── sylvia
└── mailspool
├── kent
└── sylvia
S2#gluster volume bitrot mailhome enable
S2#gluster volume bitrot mailspool enable
S2## 啟用自我修復(貌似每一台機器都要做,但必須等到作好Pool 時才能執行,這時是沒有用的)
S2#gluster volume heal mailhome enable
S2#gluster volume heal mailspool enable
|
復原重建
快樂的日子不長久,果不其然glusterS1再過了一年半載總是要壽終正寢(我們直接把S1關機)。有天忽然發現檔案異動延遲了42秒(根據gluster的參數設定,network.ping-timeout預設就是42秒)才完成。
以下我是參考這篇文章重建Gluster,它提到兩種方式,第一種方式是用一台新機取代掛點的舊機(這方式最簡單,另一個是完全重建,太複雜了),我們照著之前準備glusterS2的方式再準備一台glusterS3(是的,換個IP),然後到glusterS2作下列處理:
S2#gluster peer probe glusterS3
S2##以新的glusterS3的brick取代原本glusterS1的brick
S2#gluster volume replace-brick mailhome glusterS1:/brick/mailhome glusterS3:/brick/mailhome commit force
S2#gluster volume replace-brick mailspool glusterS1:/brick/mailspool glusterS3:/brick/mailspool commit force
S2##修復系統資料
S2#gluster volume heal mailhome full
S2#gluster volume heal mailspool full
|
是的,glusterClient除了頓42秒外,完全無感,但是我建議還是修改一下glusterClient的/etc/fstab,掛載目錄的標的指向glusterS2或glusterS3的其中一台,以免下次重開機的時侯無法連到正確的目錄。
至於第2種方式,真的是太麻煩了,自已看看吧!
異地備援
大家都知道雞蛋不能放在同一個籃子裡,所以我們還是準備一台遠端機器gluster Remote Server(DomainNme是glusterSR),gluster的異地備援採用的是主從式模式,也就是說要指定從A主機備援到B主機,備援方式採用非同步,必要時可從遠端回復。假設我們指定從glusterS1備援到glusterR。(其實用rsync一樣可以複製,但採用gluster geo的好處,它只有在檔案有變動後才會開始複製)
先設定遠端主機
SR#yum -y install ntp centos-release-gluster40
SR#yum -y install glusterfs gluster-cli glusterfs-libs glusterfs-server glusterfs-geo-replication
S1#lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vdb 252:16 0 2G 0 disk
└─vdb1 252:17 0 2G 0 part
SR#mkfs.xfs -i size=512 /dev/vdb1 && mkdir /brick && echo '/dev/vdb1 /brick xfs defaults 0 0'>>/etc/fstab && mount -a
S1#lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vdb 252:16 0 2G 0 disk
└─vdb1 252:17 0 2G 0 part /brick
SR##遠端複製,時間正確很重要
SR#systemctl enable ntpd.service && systemctl start ntpd.service
SR#systemctl enable glusterd.service && systemctl start glusterd.service
SR#mkdir /brick/{mailhome,mailspool}
SR#gluster volume create mailhome glusterSR:/brick/mailhome
SR#gluster volume create mailspool glusterSR:/brick/mailspool
SR#gluster volume start mailhome && gluster volume start mailspool
SR#gluster volume bitrot mailhome enable
SR#gluster volume bitrot mailspool enable
SR#firewall-cmd --zone=public --add-port=24007-24008/tcp --add-port=49152-49153/tcp --permanent
SR#service firewalld reload
SR#ln -s /usr/sbin/gluster /usr/local/sbin/gluster
SR#ln -s /usr/sbin/glusterfsd /usr/local/sbin/glusterfs
|
再設定來源主機
S1#yum -y install ntp glusterfs-geo-replication
S1#systemctl enable ntpd.service && systemctl start ntpd.service
S1#ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
S1#ssh-copy-id -i ~/.ssh/id_rsa root@glusterSR
root@glusterSR's password:
S1##建立公鑰
S1#gluster system:: execute gsec_create
Common secret pub file present at /var/lib/glusterd/geo-replication/common_secret.pem.pub
S1##建立兩端Session
S1#gluster volume geo-replication mailhome glusterSR::mailhome create push-pem
Creating geo-replication session between mailhome & glusterSR::mailhome has been successful
S1#gluster volume geo-replication mailspool glusterSR::mailspool create push-pem
Creating geo-replication session between mailspool & glusterSR::mailspool has been successful
S1##啟動Session
S1#gluster volume geo-replication mailhome glusterSR::mailhome start
S1#gluster volume geo-replication mailspool glusterSR::mailspool start
S1##查看狀態
S1#gluster volume geo-replication [mailhome glusterSR::mailhome] status [detail]
S1##到SC建立一些資料,然後到SR檢查是否已遠端備援
|
災難復原
當籃破蛋碎時只能從遠端復原,Gluster提供兩種災難復原,災難轉移(Failover)與災難回復(Failback),我個人傾向Failback,所以我們原地重建glusterS1,然後再把備份資料從glusterSR拷貝回來。
S1#yum -y install ntp centos-release-gluster40
SR#yum -y install glusterfs gluster-cli glusterfs-libs glusterfs-server glusterfs-geo-replication
S1#lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vdb 252:16 0 2G 0 disk
└─vdb1 252:17 0 2G 0 part
S1#mkfs.xfs -i size=512 /dev/vdb1 && mkdir /brick && echo '/dev/vdb1 /brick xfs defaults 0 0'>>/etc/fstab && mount -a
S1#lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vdb 252:16 0 2G 0 disk
└─vdb1 252:17 0 2G 0 part /brick
S1#systemctl enable ntpd.service && systemctl start ntpd.service
S1#systemctl enable glusterd.service && systemctl start glusterd.service
S1#mkdir /brick/{mailhome,mailspool}
S1#gluster volume create mailhome glusterS1:/brick/mailhome
S1#gluster volume create mailspool glusterS1:/brick/mailspool
S1#gluster volume start mailhome && gluster volume start mailspool
S1#gluster volume bitrot mailhome enable
S1#gluster volume bitrot mailspool enable
S1#firewall-cmd --zone=public --add-port=24007-24008/tcp --add-port=49152-49153/tcp --permanent
S1#service firewalld reload
S1#ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
S1#ssh-copy-id -i ~/.ssh/id_rsa root@glusterSR
root@glusterSR's password:
S1##把資料從遠端備分主機拷回來
S1#rsync -PavhS --xattrs --ignore-existing -e ssh root@glusterSR:/brick/ /brick/
S1#ln -s /usr/sbin/gluster /usr/local/sbin/gluster
S1#ln -s /usr/sbin/glusterfsd /usr/local/sbin/glusterfs
S1#gluster system:: execute gsec_create
Common secret pub file present at /var/lib/glusterd/geo-replication/common_secret.pem.pub
S1#gluster volume geo-replication mailhome glusterSR::mailhome create push-pem force
Creating geo-replication session between mailhome & glusterSR::mailhome has been successful
S1#gluster volume geo-replication mailspool glusterSR::mailspool create push-pem force
Creating geo-replication session between mailspool & glusterSR::mailspool has been successful
S1#gluster v geo mailhome glusterSR::mailhome status
|
GD2
S1#yum -y install centos-release-gluster40
S1#yum -y install glusterfs-server glusterfs-fuse glusterfs-api rpcbind glusterd2
S1#lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vdb 252:16 0 2G 0 disk
└─vdb1 252:17 0 2G 0 part
S1#mkfs.xfs -i size=512 /dev/vdb1 && mkdir /brick && echo '/dev/vdb1 /brick xfs defaults 0 0'>>/etc/fstab && mount -a
S1#mkdir /brick/{mailhome,mailspool}
S1#firewall-cmd --zone=public --add-port=111/tcp --add-port=111/udp --add-port=24007-24008/tcp --add-port=2379-2380/tcp --permanent && service firewalld reload
S1##啟動RPCBind服務
S1#systemctl enable rpcbind && systemctl start rpcbind
S1##編輯設定檔
S1#cat /etc/glusterd2/glusterd2.toml
localstatedir = "/var/lib/glusterd2"
logdir = "/var/log/glusterd2"
logfile = "glusterd2.log"
rundir = "/usr/var/run/glusterd2"
peeraddress = ":24008"
clientaddress = ":24007"
etcdcurls = "http://glusterS1:2379"
etcdpurls = "http://glusterS1:2380"
S1##啟動GD2服務
S1#systemctl enable glusterd2 && systemctl start glusterd2
S1##檢查節點狀態
S1#glustercli peer status
S1#glustercli volume create mailhome a63064a8-f0de-4f99-94b8-3fd7c8c4ad74:/brick/mailhome
S1#glustercli volume create mailspool a63064a8-f0de-4f99-94b8-3fd7c8c4ad74:/brick/mailspool
S1#glustercli volume start mailhome
S1#glustercli volume start mailspool
S1#glustercli volume status
Volume : mailhome
Volume : mailspool
|
以同樣的方法建立第二台
S2#yum -y install centos-release-gluster40
S2#yum -y install glusterfs-server glusterfs-fuse glusterfs-api rpcbind glusterd2
S2#lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vdb 252:16 0 2G 0 disk
└─vdb1 252:17 0 2G 0 part
S2#mkfs.xfs -i size=512 /dev/vdb1 && mkdir /brick && echo '/dev/vdb1 /brick xfs defaults 0 0'>>/etc/fstab && mount -a
S2#mkdir /brick/{mailhome,mailspool}
S2#firewall-cmd --zone=public --add-port=111/tcp --add-port=111/udp --add-port=24007-24008/tcp --add-port=2379-2380/tcp --permanent && service firewalld reload
S2#systemctl enable rpcbind && systemctl start rpcbind
S2#cat /etc/glusterd2/glusterd2.toml
localstatedir = "/var/lib/glusterd2"
logdir = "/var/log/glusterd2"
logfile = "glusterd2.log"
rundir = "/usr/var/run/glusterd2"
peeraddress = ":24008"
clientaddress = ":24007"
etcdcurls = "http://glusterS2:2379"
etcdpurls = "http://glusterS2:2380"
S2#systemctl enable glusterd2 && systemctl start glusterd2
S2#glustercli peer status
|
S1##串連新節點
S1#glustercli peer probe 192.168.10.99
S1#glustercli peer status
Failed to get Peers list
Error: Get http://localhost:24007/v1/peers: net/http: timeout awaiting response headers
S1##再試試可不可以建立volume
S1#glustercli volume create mailhome a63064a8-f0de-4f99-94b8-3fd7c8c4ad74:/brick/mailhome b222f7af-4e13-4448-8ea0-86d8c8846c43:/brick/mailhome
Volume creation failed
Error: Post http://localhost:24007/v1/volumes: net/http: timeout awaiting response headers
S1#
|
後記
也許你會想Gluster是否可以拿來當資料庫的檔案系統,理論上是可以但原則上不建議,以我所裝的Postgresql來說,我sort了一下,資料檔從十幾MB到1GB的都有,資料庫檔案通常很大,動輒要同步那麼多檔案,除非你的硬體與網速都很強大,話說回來,有那麼多錢,何不裝RAID?
剛試完Gluster後,馬上又看到另二個儲存架構Ceph與Swift,大概找了一下,不外乎是企業級架構、軟體定義儲存,和Gluster最大的不同是,Gluster是以檔案為單位,所以大檔在備份的時侯要較長的時間,而企業級架構則是把檔案拆成更小單位(所以不見得快),然後分散儲存到不同的地方。
至於資料庫的保全方式,顯然以檔案系統的方式來做HA不是那麼合適,解決的方式不外乎是尋找分散式的資料庫系統,但能找的到的大都是NOSQL,唯一貼近SQLDB的大概就是CockroachDB了,或許也是一個不錯的選擇。
另外把設定整個搞亂了怎麼辦?把 /var/lib/glusterd砍掉後重開機,則一切設定全清空
2018/9/12 PS:
今天我試了openwebmail,它有個大缺點,就是一個folder就是一個檔案,我試了一個7G的檔案變動(把mail移動),對glusterS2的複製目錄執行 ls -l,幾乎以為檔案舜間拷貝完成,但改用 ls -ls去看時,才發現拷貝還在繼續,而openwebmail就此被Lock住直到拷貝完成才繼續運做,我們任誰碰到這種狀況都應該是無法接受的。另外把設定整個搞亂了怎麼辦?把 /var/lib/glusterd砍掉後重開機,則一切設定全清空
留言
張貼留言