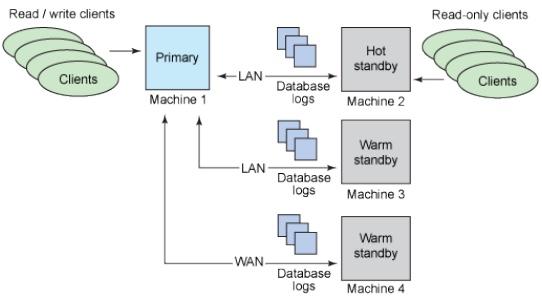
Postgresql HA
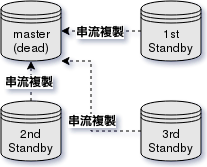
Standby databases
主要資料庫的備分,有著與主要資料庫相同的資料,以備意外發生。
以複製方式分類
Physical standbys:硬碟區塊複製
Logical standbys:變動資料串流複製
以transaction同步分類:
異步:可能會掉資料
同步:不可能掉資料,master會等待standby複製完成通知
以用途分類
Warm standbys:standby機不提供連線
Hot standbys:standby機提供唯讀查詢連線
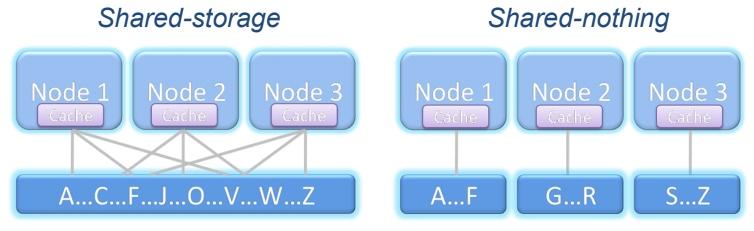
叢集
多個主機視為一體,叢集規模可調整,任一節點掛點不影響作業,依資料共用可分類如下:
Shared-storage:所有節點共享資料
Shared-nothing:每個節點有自已的儲存,所以不一定會資料相同
然後是我比較關注的免費產品介紹:
Ruberep
異步、多master與多平台解決方案,適用於Postgresql與MySQL,奠基於trigger,不支援DDL、User與Grants
Pgpool II
是個中介軟體。主要功能如下:

- Connection pool
- Replication
- Load balancing
- Automatic failover
- Parallel queries
- Limiting Exceeding Connections
Bucardo
描述功能看起來很強大,但缺點也不少,暫不考慮
PostgresXL
只能用一個awesome形容,PostgressXL屬於企業集架構的大型叢集,前身是Postgres-XC,功能強大,效能卓越,但因為採用shared nothing、分散式表格儲存(也就是多筆資料會分別儲存到不同節點,所以她的查詢是採平行處理,速度快,但也就是節點要比較多),成本相對也不便宜。
看起來pgpool-II是個不錯的選擇,以下是個合適的架構
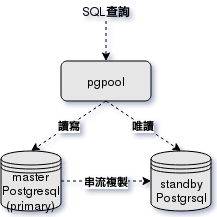 |
pgpoo-II有多種執行模式,官方建議使用streaming replication搭配synchronous_commit = remote_apply進行複寫(也就是pgpool-II不負責資料抄寫)。
左圖的架構是:
客戶端與pgpool互動,資料只寫入primary(master),然後master再複製到其它standbys。
當primary掛掉時,pgpool可協調standby轉成master以保證資料不流失。
但缺點也很明顯,pgpool掛掉時,就得停機修復pgpool。
如果只有一台standby,我覺得是沒有問題的,但如果有多台standbys,當master掛掉時,很有可能兩個pgpools各自選擇不同的standeby作為master,那麼你的資料就會一團亂,所幸pgpool ver 3.3後改善了這情況。
|
Postgresql Streaming replication
首先,我們先搞定stream replication,首先準備兩台機器master與standby(兩台都是CentOS7),一台是master,別一台做為standby,因為CentOS只提供到9.2版,而複製功能則到9.4後才比較完善,所以我們直接裝10版
另外兩台最好都安裝較時軟體,因為WAL內有有時間戳記。
#yum install https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-7-x86_64/pgdg-centos10-10-2.noarch.rpm
#yum -y install postgresql10-contrib postgresql10-server tar rsync
|
然後初始化master的資料庫並設定
master##初始化資料庫
master#/usr/pgsql-10/bin/postgresql-10-setup initdb
master#su - postgres -c "vi 10/data/pg_hba.conf" && grep "^[^#;]" /var/lib/pgsql/10/data/pg_hba.conf
master##編輯資料庫設定檔
master#su - postgres -c "vi 10/data/postgresql.conf"
listen_addresses = '*' ↲
unix_socket_directories = '/var/run/postgresql, /tmp'↲
password_encryption = md5↲
wal_level = replica↲#10之前的版本設為hot_standby
synchronous_commit = remote_write↲
archive_command = 'test ! -f "/var/lib/pgsql/10/backups/%f" && cp "%p" "/var/lib/pgsql/10/backups/%f"'↲#拷貝WAL到特定目錄的命令
max_wal_senders = 3↲#standby的最大連線數
wal_keep_segments = 8↲#pg_xlog目錄的過去日誌最小儲存空間
max_replication_slots = 10↲#複製的暫存槽數,9.4+,用來防止崩潰的暫存資料
master##設定與啟動資料庫服務
master#systemctl enable postgresql-10.service && systemctl start postgresql-10.service
master##設定postgresql密碼
master#psql -U postgres -c "ALTER USER postgres PASSWORD 'pass4pg';"
ALTER ROLE
master##建立複製用戶
master#psql -U postgres -c "CREATE USER replicator REPLICATION LOGIN ENCRYPTED PASSWORD 'pass4rep';"
^C (若使用同步復製,必須強迫中斷,因為第2台postgresql未建立,不可能拷貝成功)
master##用以下指令檢查資料庫狀態是不是為parimary
master#/usr/pgsql-10/bin/pg_controldata /var/lib/pgsql/10/data/|grep cluster
Database cluster state: in production
master##開啟防火牆
master#firewall-cmd --add-service=postgresql --permanent && service firewalld reload
master##設定postgres密碼,因為要透過scp傳送WAL
master#echo "pass4master" | passwd --stdin postgres
|
準備standby
standby##先把master資料庫複製過來
standby#pg_basebackup -h 192.168.10.master -D /var/lib/pgsql/10/data -U replicator -v -P -R -X stream && chown -R postgres:postgres /var/lib/pgsql/10/data/
Password:pass4rep
standby##修改資料設定檔
standby#su - postgres -c "vi 10/data/postgresql.conf"
archive_command = 'test ! -f "/var/lib/pgsql/10/backups/%f" && cp "%p" "/var/lib/pgsql/10/backups/%f"'↲
hot_standby = on
standby_mode = 'on'↲
primary_conninfo = 'user=replicator password=pass4rep host=192.168.10.master port=5432 application_name=SyncTest sslmode=prefer sslcompression=1 target_session_attrs=any'↲
restore_command = 'scp 192.168.10.master:/var/lib/pgsql/10/backups/%f %p'↲
trigger_file='/var/lib/pgsql/switch_2_master'#出現這個檔案時,切換成master
standby##開啟防火牆
standby#firewall-cmd --add-service=postgresql --permanent && service firewalld reload
standby##設定與啟動資料庫服務
standby#systemctl enable postgresql-10.service && systemctl start postgresql-10.service
standby##用以下指令檢查資料庫狀態是不是為standby
standby#/usr/pgsql-10/bin/pg_controldata /var/lib/pgsql/10/data/|grep cluster
Database cluster state: in archive recovery
standby##因為要透過scp拷貝WAL,所以設定免密碼連線到master
standby#su - postgres -c ssh-keygen
Enter file in which to save the key (/var/lib/pgsql/.ssh/id_rsa): ↲
Your public key has been saved in /var/lib/pgsql/.ssh/id_rsa.pub.↲
Enter passphrase (empty for no passphrase): ↲
Enter same passphrase again:↲
Your identification has been saved in /var/lib/pgsql/.ssh/id_rsa.↲
Your public key has been saved in /var/lib/pgsql/.ssh/id_rsa.pub.↲
+---[RSA 2048]----+
| .oE+*=+.. |
+----[SHA256]-----+
standby#ssh-copy-id -i /var/lib/pgsql/.ssh/id_rsa.pub postgres@192.168.10.master
postgres@192.168.10.master's password:pass4master
standby##準備讓第三方進來,例如pgpoolII
standby#echo "pass4standby" | passwd --stdin postgres
standby##讓第三方軟體,例如pgpool可以免密碼連線
standby#mkdir /var/lib/pgsql/.ssh
standby#chcon -R -t ssh_home_t /var/lib/pgsql/.ssh
standby##設定postgres密碼,後面測試pg_rewind時會用到
standby#echo "pass4standby" | passwd --stdin postgres
|
回到master繼續,建立測試資料庫與資料
master##讓standby可以免密碼連線
master#chcon -R -t ssh_home_t /var/lib/pgsql/.ssh
master##建立資料庫
master#su - postgres -c "/usr/bin/createdb -E UTF8 -U postgres test"
master##建立表格與資料
master#echo "CREATE TABLE test(id SERIAL PRIMARY KEY,txt text);INSERT INTO test(txt)VALUES('Test');"|/usr/bin/psql -U postgres test
CREATE TABLE
INSERT 0 1
master#
|
到standby查詢資料
standby#psql -U postgres -d test -c "SELECT * FROM test;"
(1 rows)
standby#
|
Pgpool II
現在我們要準備一台pgpooI1專用機來存取master與standby的Middleware,
pgpool1# useradd -r -u 26 -m -d /var/lib/pgsql postgres↲
pgpool1#su - postgres -c ssh-keygen↲
Generating public/private rsa key pair.↲
Enter file in which to save the key (/var/lib/pgsql/.ssh/id_rsa): ↲
Enter passphrase (empty for no passphrase): ↲
Enter same passphrase again: ↲
Your identification has been saved in /var/lib/pgsql/.ssh/id_rsa.↲
Your public key has been saved in /var/lig/pgsql/.ssh/id_rsa.pub.↲
The key's randomart image is:
+---[RSA 2048]----+
|o=o+.+. o. |
+----[SHA256]-----+
pgpool1#ssh-copy-id -i /var/lib/pgsql/.ssh/id_rsa.pub postgres@192.168.10.standby
postgres@192.168.10.standby's password:pass4standby
pgpool1#yum -y install http://www.pgpool.net/yum/rpms/3.7/redhat/rhel-7-x86_64/pgpool-II-release-3.7-1.noarch.rpm
pgpool1#yum -y install pgpool-II-pg10
pgpoo1# #參考這篇文章,讓pgpool以非 root 用戶執行
pgpoo1#grep -A3 Service /lib/systemd/system/pgpool.service#修改service檔案 [Service] User=postgres Group=postgres EnvironmentFile=-/etc/sysconfig/pgpool pgpool1#chown postgres:postgres /var/run/pgpool pgpool1#vi /usr/lib/tmpfiles.d/pgpool-II-pg10.conf d /var/run/pgpool 0755 postgres postgres - pgpool1#chown -R postgres:postgres /etc/pgpool-II/ pgpool1#mkdir /var/lib/pgsql/sbin pgpool1#chown postgres:postgres /var/lib/pgsql/sbin pgpool1#chmod 700 /var/lib/pgsql/sbin pgpool1#cp /sbin/ifconfig /var/lib/pgsql/sbin pgpool1#cp /sbin/arping /var/lib/pgsql/sbin pgpool1#cp /sbin/ip /var/lib/pgsql/sbin pgpool1#chmod 4755 /var/lib/pgsql/sbin/ip pgpool1#chmod 4755 /var/lib/pgsql/sbin/ pgpool1#chmod 4755 /var/lib/pgsql/sbin/arping pgpool1##修改設定檔
pgpool1#cd /etc/pgpool-II/
pgpool1#mv pgpool.conf pgpool.conf.original
pgpool1#cp pgpool.conf.sample-stream pgpool.conf
pgpool1#vi pgpool.conf
listen_addresses = '*'↲
port = 5432↲
#設定後端(從0開始,0表示為primary資料庫,0以後為standby資料庫)
backend_hostname0 = '192.168.10.master'↲
backend_data_directory0 = '/var/lib/pgsql/10/data'↲
backend_flag0 = 'ALLOW_TO_FAILOVER'↲
backend_hostname1 = '192.168.10.standby'↲
backend_port1 = 5432↲
backend_weight1 = 1↲
backend_data_directory1 = '/var/lib/pgsql/10/data'↲
backend_flag1 = 'ALLOW_TO_FAILOVER'↲
sr_check_user = 'replicator'↲ #複製用戶帳號,用以檢查stream replication
sr_check_password = 'pass4rep'↲
health_check_period = 2↲ #每2秒查一次資料庫是否還健在
health_check_user = 'postgres'↲
health_check_password = 'pass4pg'↲
health_check_database = 'postgres'
#改變路徑
if_cmd_path = '/var/lib/pgsql/sbin' arping_path = '/var/lib/pgsql/sbin' #當master故障時所要執行的指令,我們可以在此指定一個Shell,連線到standby插入一個trigger_file ,讓standby變成primary,但遺憾的是,不見得每次都會成功
failover_command =’/etc/pgpool-II/failover_stream.sh %d %P %H /var/lib/pgsql/switch_2_master’↲
failover_command =’/etc/pgpool-II/failover_stream.sh %d %P %H %R’↲
failback_command=↲
#授權管理,我們之前把資料庫驗證設為md5,pgpool無法通透,只好啟用enable_pool_hba並另外設定pool_hba.conf
enable_pool_hba = on
pgpool1#vi /etc/pgpool-II/pool_hba.conf
pgpool1##下列是master掛點時,升級standby的指令,當然最後可以用msmtp加上寄信通知
pgpool1#vi /etc/pgpool-II/failover_stream.sh
#! /bin/sh -x↲
FAILED_NODE_ID=${1}↲
OLD_PRIMARY_NODE_ID=${2}↲
NEW_MASTER_NODE_HOST=${3}↲
TRIGGER_FILE=${4}↲
NEW_MASTER_DATA_FOLDER=${4}↲
if [ "${FAILED_NODE_ID}" == "${OLD_PRIMARY_NODE_ID}" ]; then↲
#ssh -T postgres@${NEW_MASTER_NODE_HOST} "/usr/bin/touch ${TRIGGER_FILE}"↲
ssh -T postgres@${NEW_MASTER_NODE_HOST} /usr/pgsql-10/bin/pg_ctl promote -D ${NEW_MASTER_DATA_FOLDER}↲
fi↲
exit 0;
pgpool1#chmod +x /etc/pgpool-II/failover_stream.sh
pgpool1##然後建立用戶帳號(要跟資料庫設定的相同)
pgpool1#pg_md5 --md5auth --username=postgres pass4pg
pgpool1#pg_md5 --md5auth --username=replicator pass4rep
pgpool1##開啟防火牆
pgpool1#firewall-cmd --add-service=postgresql --permanent && service firewalld reload
pgpool1##啟用服務
pgpool1#systemctl enable pgpool.service && systemctl start pgpool.service
|
然後我們到standby下執行sql
standby#echo "INSERT INTO test(txt) values('pgpool');SELECT * FROM test;"|/usr/bin/psql -h 192.168.10.pgpool1 -U postgres -d test
Password for user postgres: pass4pg
INSERT 0 1
(2 rows)
standby#
|
WatchDog
前面有提過pgpool可以管理Postgresql的HA,但怕的是pgpool本身掛掉,所以在3.2版以後才出現WatchDag讓pgpool本身可以做HA,所以我們可以安裝多個pgpool,然後啟動各自的WatchDog,然後她們會自已決定誰當老大(master),然後就互相監視,直到老大掛掉,剩下有啟動WatchDog的pgpools,重新選出新的老大,當老大上任時,會透過if_up_cmd把一個delegate_IP加到特定的網卡,當pgpool服務下線時,會把透過if_down_cmd的設定把delegate_IP從特定的網卡中移除。也就是說在pgpool ha的狀態下,這個網址會一直存在,對於有Connection Pool機制的程式,就不用擔心程式因為無法連資料庫而掛掉。
首先我先修改pgpool1的設定如下:
pgpool1#vi /etc/pgpool-II/pgpool.conf
use_watchdog = on↲#啟用WatchDog
trusted_servers = '192.168.10.pgpool2'↲#用ping其它主機,可為選舉master的決策參考
wd_hostname = '192.168.10.pgpoo1'↲#本身的IP
wd_port = 9000↲#本身WatchDog的監聽埠
delegate_IP = '192.168.10.dip'↲#供客戶端連線的位址,程式查詢
if_up_cmd = 'ip addr add $_IP_$/24 dev eth0 label eth0:0'↲#如果對客戶服務的網卡不是eth0,請自行修改
if_down_cmd = 'ip addr del $_IP_$/24 dev eth0'↲#如果對客戶服務的網卡不是eth0,請自行修改
wd_interval =3↲#每隔3秒,進行存活測試
heartbeat_destination0 = '192.168.10.pgpool2'↲#發送heartbeat到此目的位址
heartbeat_destination_port0 = 9694↲#發送heartbeat到目的埠
other_pgpool_hostname0 = '192.168.10.pgpool2'↲#要監控的其它主機
other_pgpool_port0 = 5432↲#這個設定不清楚有什麼用處,但要不設不行
other_wd_port0 = 9000↲#要監控的其它主機的WatchDog的埠
pgpool1#
pgpool1##開啟防火牆
pgpool1#firewall-cmd --add-port=9000/tcp --add-port=9694/tcp --permanent && service firewalld reload
pgpool1##重啟服務
pgpool1#systemctl reload pgpool.service
pgpool1##檢查網卡
pgpool1#ip a list eth0
inet 192.168.10.pool1/24 brd 192.168.10.255 scope global eth0↲
valid_lft forever preferred_lft forever↲
inet 192.168.10.dip/24 scope global secondary eth0:0↲
valid_lft forever preferred_lft forever
pgpool1#
|
現在我們建立另一台pgpool2做為HA
pgpool2##首先照之前裝pgpool1的過程從ssh-keygen做到yum安裝軟體
pgpool2##....裝好後,把pgpool1的設定檔拷過來
pgpool2#cd /etc/pgpool-II/ && scp root@192.168.10.pgpoo1:'/etc/pgpool-II/pgpool.conf /etc/pgpool-II/failover_stream.sh /etc/pgpool-II/pool_hba.conf /etc/pgpool-II/pool_passwd' ./
pgpool2##修改設定
pgpool2#vi /etc/pgpool-II/pgpool.conf
use_watchdog = on↲#啟用WatchDog
trusted_servers = '192.168.10.pgpool1'↲#用ping其它主機,可為選舉master的決策參考
wd_hostname = '192.168.10.pgpoo2'↲#本身的IP
if_up_cmd = 'ip addr add $_IP_$/24 dev eth0 label eth0:0'↲#如果對客戶服務的網卡不是eth0,請自行修改
if_down_cmd = 'ip addr del $_IP_$/24 dev eth0'↲#如果對客戶服務的網卡不是eth0,請自行修改
heartbeat_destination0 = '192.168.10.pgpool1'↲#發送heartbeat到此目的位址
other_pgpool_hostname0 = '192.168.10.pgpool1'↲#要監控的其它主機
pgpool2##開啟防火牆
pgpool2#firewall-cmd --add-service=postgresql --add-port=9000/tcp --add-port=9694/tcp --permanent && service firewalld reload
pgpool2##啟用服務
pgpool2#systemctl enable pgpool.service && systemctl start pgpool.service
pgpool2#
|
然後我們到standyby下查詢
standby#psql -h 192.168.10.dip -U postgres -d test -c "SELECT * FROM test;"
Password for user postgres: pass4pg
INSERT 0 1
(2 rows)
standby#
|
然後我們可以驗證一下,把pgpool1的服務關務,過個3秒鐘,再到standby,仍然可以進行查詢。
查詢快取
資料庫測試
之前所有的Lab都是在VM上實做,在測試之前,我都先做了一份Snapshop,現在我們把master的資料庫服務關閉
master##先看一下pgpool的狀態
master#psql -h 192.168.10.dip -U postgres -c "SHOW POOL_NODES;"
master##停止資料庫
master#systemctl stop postgresql-10.service
master##檢查資料庫狀態
master#/usr/pgsql-10/bin/pg_controldata /var/lib/pgsql/10/data/|grep cluster
Database cluster state: shut down
|
再到standby查看情況
standby#/usr/pgsql-10/bin/pg_controldata /var/lib/pgsql/10/data/|grep cluster
Database cluster state: in production
standby#psql -h 192.168.10.dip -U postgres -c "SHOW POOL_NODES;"
|
明顯standby已接手升級為master(primary),然後我到master重啟資料庫
master#systemctl start postgresql-10.service
master#/usr/pgsql-10/bin/pg_controldata /var/lib/pgsql/10/data/|grep cluster
Database cluster state: in production
master#psql -h 192.168.10.dip -U postgres -c "SHOW POOL_NODES;"
|
即使重新把master重新處理好,再把pgpool重新啟動,pgpool仍然會視standby為主要資料庫,而master也仍被視為down狀態。
pg_rewind
常常我們會為了維護的原因,把資料庫下線,當然pgpool會自動把standby升級為maser。Postgresql從9.5版起提供了pg_rewind功能可以幫助已經正常下線的資料庫更新並重新變成新的standby,以減少回復時間,但是它有前提:必須啟用wal_log_hints與full_page_writes(必須重啟資料庫),但是這是以效能換取低風險,我的建議是打開使用,畢竟,維護系統,幾年內總是會發生一次(另外效能調整可以參考這裡)。
master##停用資料庫,然後pgpool會把standby升級成primary
master#systemctl stop postgresql-10 stop
master##維護完成後,要重新把資料庫掛回來,切換身分為postgres
master#su - postgres
pg@master##重要:一定要重啟資料庫再關閉,pg_rewind才會作用(原因不明)
pg@master#/usr/pgsql-10/bin/pg_ctl start -D ~/10/data && /usr/pgsql-10/bin/pg_ctl stop -D ~/10/data
pg@master##把standby資料庫的變動同步回來
pg@master#/usr/pgsql-10/bin/pg_rewind -D ~/10/data/ --source-server='host=192.168.10.standby port=5432 user=postgres password=pass4pg' -P
connected to server↲
servers diverged at WAL location 0/D000098 on timeline 1↲
…
syncing target data directoryd↲
Done!
pg@master#vi 10/data/postgresql.conf
hot_standby = on
pg@master#mv 10/data/recovery.done 10/data/recovery.conf&&vi 10/data/recovery.conf
pg@master#su - postgres -c ssh-keygen
Enter file in which to save the key (/var/lib/pgsql/.ssh/id_rsa): ↲
Your public key has been saved in /var/lib/pgsql/.ssh/id_rsa.pub.↲
Enter passphrase (empty for no passphrase): ↲
Enter same passphrase again:↲
Your identification has been saved in /var/lib/pgsql/.ssh/id_rsa.↲
Your public key has been saved in /var/lib/pgsql/.ssh/id_rsa.pub.↲
+---[RSA 2048]----+
| .oE+*=+.. |
+----[SHA256]-----+
pg@master#ssh-copy-id -i /var/lib/pgsql/.ssh/id_rsa.pub postgres@192.168.10.standby
postgres@192.168.10.master's password:pass4standby
pg@master#exit
master##重啟資料庫服務
master#systemctl start postgresql-10.service
master##查看資料庫狀態
master#/usr/pgsql-10/bin/pg_controldata /var/lib/pgsql/10/data/|grep cluster
Database cluster state: in archive recovery
master##看一下master的節點編號與狀態
master#psql -h 192.168.10.dip -U postgres -c "SHOW POOL_NODES;"
|
然後我們到pgpool1把node 0 (192.168.10.master) 重新上線
pgpool1##我們先為pgpool設定一個管理員/密碼(如果沒有)
pgpool1#echo "pcpadmin:`pg_md5 pass4admin`">>/etc/pgpool-II/pcp.conf
pgpool1##把node 0 重新上線管理
Password:pass4admin
pcp_attach_node -- Command Successful
pgpool1##檢視node 0 狀態
Password:pass4admin
192.168.10.master 5432 2 0.500000 up standby
|
註:對應的命令有一個pcp_detach_node可以把節點離線
如果 detach node亂掉以致pgpool上不起來查看一下 $ls -la /tmp ,把相關的暫存檔砍掉後重上pgpool
如果 detach node亂掉以致pgpool上不起來查看一下 $ls -la /tmp ,把相關的暫存檔砍掉後重上pgpool
資料庫維護
因為我採取的模式,資料同步的動作是由Postgres自行完成,所以有時候會把 master的服務restart,但是PGPool在連不上master的時候會逕自把standby給升級成master,所以這時正確的做法是先把 PGPool的所有節點卸載(按順序先standby再master),等到維護完成後再一一掛載(先master再standby,第一個掛上的會被視為master)。因為資料庫必須經常維護,所以也懶得每次打pcpadmin的密碼(pass4admin),所以做法如下(可以把卸掛單獨寫成shell),但是要注意的是,卸載slave 節點,再重上沒有問題,若是primary被卸下,則pcp_attach_node會無法重上。
pgpool1#echo ‘127.0.0.1:9898:pcpadmin:pass4admin’ > ~/.pcppass↲
pgpool1##卸載節點
pgpool1#PCPPASSFILE=~/.pcppass pcp_detach_node -h 127.0.0.1 -U pcpadmin -p 98988 -w -n 1↲
pgpool1#PCPPASSFILE=~/.pcppass pcp_detach_node -h 127.0.0.1 -U pcpadmin -p 98988 -w -n 0↲
pgpool1##離開去維護資料庫,完成後再回來掛載
pgpool1#PCPPASSFILE=/root/.pcppass pcp_attach_node -h 127.0.0.1 -U pcpadmin -p 9898 -n 0 -v -w↲
pgpool1#PCPPASSFILE=/root/.pcppass pcp_attach_node -h 127.0.0.1 -U pcpadmin -p 9898 -n 1 -v -w↲
Onlie Recovery
pgpool1#echo ‘127.0.0.1:9898:pcpadmin:pass4admin’ > ~/.pcppass↲
pgpool1##卸載節點
pgpool1#PCPPASSFILE=~/.pcppass pcp_detach_node -h 127.0.0.1 -U pcpadmin -p 98988 -w -n 1↲
pgpool1#PCPPASSFILE=~/.pcppass pcp_detach_node -h 127.0.0.1 -U pcpadmin -p 98988 -w -n 0↲
pgpool1##離開去維護資料庫,完成後再回來掛載
pgpool1#PCPPASSFILE=/root/.pcppass pcp_attach_node -h 127.0.0.1 -U pcpadmin -p 9898 -n 0 -v -w↲
pgpool1#PCPPASSFILE=/root/.pcppass pcp_attach_node -h 127.0.0.1 -U pcpadmin -p 9898 -n 1 -v -w↲
|
要注意的是follow_master_command的設定,官方說:指定命令在master錯誤移轉(failover_command)完成後執行,在中文手冊也提到:通常,這個命令應該用於調用例如 pcp_recovery_node 命令來從新的主節點恢復備節點, 根本沒有解釋清楚,這裡說的比較正確:當standby其中一台升級為primary時,其它的standby必須重新認這台新的primary為主而不是連到舊的primary,所以pgpool會failover_command執行完成後,呼叫每個standby的follow_master_command,然後透過這個命令,然後在這個命令shell,叫用pcp_recovery_node(若在pgpool的設定叫用pcp_recovery_node必須先建立預設密碼),來重新設定這個standby,pcp_recovery_node會先執行recovery_1st_stage_command後再叫的recovery_2nd_stage_command所指定的命令(只針對parimary(master)且只有replication_mode有用,所以此文不會用到),最後再執行事先建立好放在資料庫資料目錄下的pgpool_remote_start(注意:官方範例,把此命令與叫recovery_1st_stage_command都放在資料庫的data目錄下)來啟動資料庫,整個過程如下:
 |
→
|
一般來說小公司沒這個有錢,頂多放2台實機跑資料庫,兩台VM跑pgpool,應該就夠用了,本來我要測試,當master硬體掛點,然後重建這台master(不要像之前用手動建立),透過pcp_recovery_node自動拷貝資料並掛載為standby.
但是我手動執行下列指令,卻遇到錯誤(為什麼是pgpool當來源資料庫?因為實際運行時,只有pgpool才知道那個才是primary)
master#su - potgres
pg@master#pg_basebackup -h 192.168.10.pgpool1 -U replicator -D /var/lib/pgsql/10/data -R -X stream -c fast
Password:pass4rep↲
DETAIL: EOF encountered with backend↲
pg_basebackup: child process exited with error 1↲
pg_basebackup: removing contents of data directory "/var/lib/pgsql/10/data"
|
因為recovery_1st_stage_command傳入的4個參數並未告知目前primary db的IP是那個,所以官方範例是透過執行中的pgpool來做base backup,但很可惜,這裡有人問”pg_basebackup with streaming replication option over pgpool”,但得到的答案是:"Well, pgpool-II is not supoosed to work with pg_basebackup in such a way."
所以Online Recovery對於使用streaming replication的這個Lab來說,是沒有意義的,也就是說:資料庫其實準備兩台就夠了,而且failover_command加入Email通知就變的迫切需要。或許有人會想要採取以下架購:
 |
What happens if the primary server goes down? In this case, one of remaining standby server is promoted to new primary server.
所以當master掛掉時,standby中的其中一個可以升級為primary,但沒有說保證會是那一個。
或者可以這樣做:pgpool啟動後,把2nd standby pcp_detach_node以保證只剩1st standby等待升級,當failover_command通知後,再手動把2nd standby pcp_attach_node後,再去處理失敗的master。
尾聲
除了對pgpool進行SQL查詢 “SHOW POOL_NODES;” 外可以得到節點組成狀態外,另外我們也可以對primary(master)進行以下查詢,查得到就是master,查不到則是standby。
master#psql -h 127.0.0.1 -U postgres -c "SELECT application_name,state,usename,sync_priority,sync_state FROM pg_stat_replication;"
(1 row)
| ||||||||||||
pgpool1#pcp_promote_node -w -n 1
FATAL: invalid pgpool mode for process recovery request↲
DETAIL: specified node is already primary node, can't promote node id 1
|
出現錯誤,雖然master切換到standby,但是standby並沒有真的變成paimary。
standby#psql -h 192.168.10.dip -U postgres -c "SHOW POOL_NODES;"
standby#psql -h 127.0.0.1 -U postgres -c "SELECT application_name,state,usename,sync_priority,sync_state FROM pg_stat_replication;"
(0 rows)
| ||||||||||||||||||||||||
那麼再切回來呢?
pgpool1#pcp_promote_node -w -n 0
pcp_promote_node -- Command Successful
|
成功了,看一下結果:
standby#psql -h 192.168.10.dip -U postgres -c "SHOW POOL_NODES;"
standby##Oh...Shit!
|
狀態一點也沒有好轉,所以鄭重告誡:streaming replication下,千萬不要手動去升級standby。
後記
PGPoll 的設定預設是把load_balance_mode開啟(on),官方文件說了:沒有Transaction的查詢會走StandBy Server,所以我面臨了跟這裡類似的問題,交易完成的瞬間,進行查詢,結果StanBy Server還來不及更新,結果查到的是之前的Record,所以您可能要考慮把load_balance_mode設為off來避免此種狀況。參數調整
listen_backlog_multiplier(integer)
指定從前端到Pgpool-II的連線的佇列長度。佇列長度(實際上是listen()系統調用的"backlog"參數)定義為listen_backlog_multiplier * num_init_children。
"backlog"的最大值依系統而定,根據https://linux.die.net/man/2/listen的說法,Linux2.2以後,backlog是等待accept真正完成連線的Socket,對於未完成連線的Socket的可以佇列的數量是/proc/sys/net/ipv4/tcp_max_syn_backlog。所以內核要維護兩個佇列
若是backlog的數量設定超過/proc/sys/net/core/somaxconn的值,將會悄悄的被砍掉。
"backlog"的最大值依系統而定,根據https://linux.die.net/man/2/listen的說法,Linux2.2以後,backlog是等待accept真正完成連線的Socket,對於未完成連線的Socket的可以佇列的數量是/proc/sys/net/ipv4/tcp_max_syn_backlog。所以內核要維護兩個佇列
若是backlog的數量設定超過/proc/sys/net/core/somaxconn的值,將會悄悄的被砍掉。
num_init_children (integer)
預分支的Pgpool-II服務器進程的數量。預設值為32。num_init_children也是客戶端到Pgpool-II的同時連線限制。如果嘗試連線到Pgpool-II的客戶端的個數超過num_init_children,它們將被阻塞(不會因錯誤而被拒絕,例如PostgreSQL),直到關閉與任何Pgpool-II進程的連線,除非reserved_connections設置為1或更大。
內核維護一個"監聽佇列",其長度稱為 backlog(依系統不同而有其上限),如果num_init_children*listen_backlog_multiplier超過這個數,則必須加大backlog的數目,否則可能發生下列事故:
- 連線到pgpool失敗
- 由於重新嘗試連線,拖慢系統
如果監聽佇列過載,用"netstat -s|grep overflowed"
561 times the listen queue of a socket overflowed
若出現上列訊息,則肯定是過載了,此時必須加大backlog
pgpool1#sysctl net.core.somaxconn
net.core.somaxconn = 128
pgpool1#sysctl -w net.core.somaxconn = 256 |
或是把下面這行加到/etc/sysctl.conf
net.core.somaxconn = 256 |
每個Postgresql的連線大約是 max_pool*num_init_children.
想要取消查詢會建立另一個與後端的連線;因此,如果所有連線都在使用中,則無法取消查詢。如果要確保可以取消查詢,請將此值設置為預期連線的兩倍。
另外,PostgreSQL允許非超級用戶的同時連線最大為max_connections-superuser_reserved_connections(預設是3)。
所以總體參數必須滿足下列公式,沒有取消查詢的需求的情況
max_pool*num_init_children <= (max_connections - superuser_reserved_connections) |
有取消查詢的需求的情況
max_pool*num_init_children*2 <= (max_connections - superuser_reserved_connections) |
max_pool (integer)
每個pgpool子process可以連線快取的數量,相同用戶名與相同的執行時期參數才會快取,否則以新連線連線到資料庫。若快取連線超出max_pool時,取消舊連線並以新連線替代
reserved_connections (integer,預設是0)
其值若大於0時,若目前客端連線數超過num_init_children - reserved_connections,連線的客戶端將被拒絕連線並收到"抱歉,已經有過多客戶連線"的訊息。例如reserved_connections = 1且num_init_children = 32時,則第32個客戶連線將被拒絕。
此行為與PostgreSQL類似,對於客戶端連接數量大且每個Session可能需要很長時間的系統來說非常有用。在這種情況下,偵聽隊列的長度可能會很長,並且可能導致系統不穩定。在這種情況下,將此參數設置為非0是一個很好的主意,以防止偵聽隊列變得很長。
留言
張貼留言